This article accompanies the talk and shares a preview of references for the Slack engineering blog article on how Slack implemented circuit breakers in internal tooling.
🎉🍿 Here from Craft Conference? Tweet and say hi!
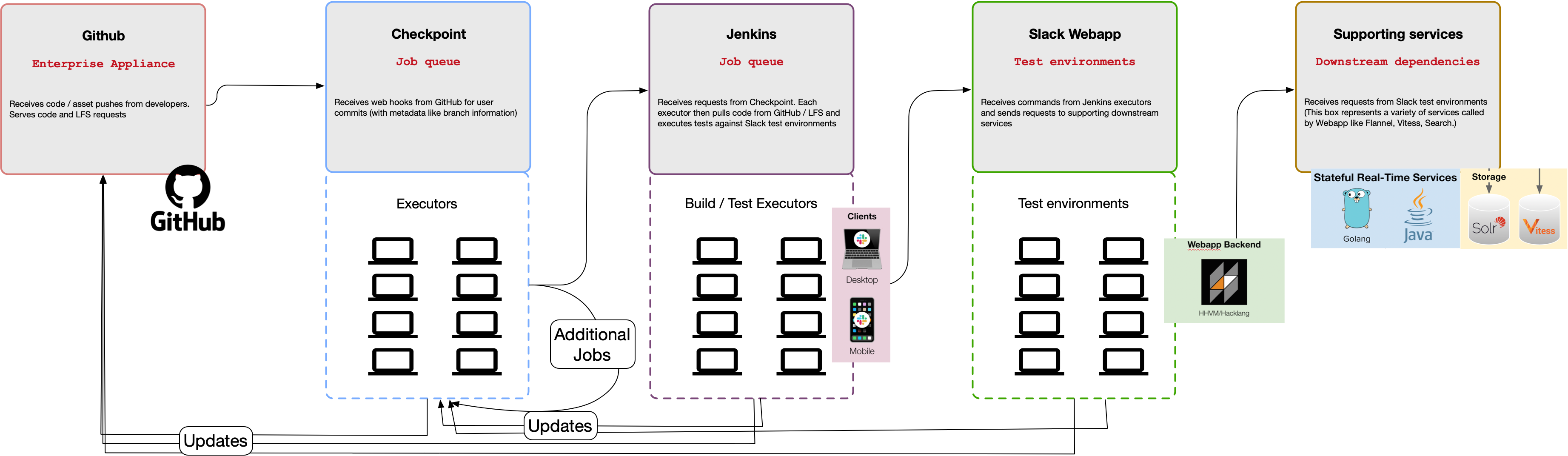
💡 Abstract
After months of similar cascading incidents, Frank Chen shares how Slack engineers increased developer productivity by implementing circuit breakers throughout internal tooling. Engineers across Developer Productivity teams at Slack applied friction or shed to requests in Checkpoint, a Continuous Integration (CI) / Continuous Delivery (CD) orchestration service. This methodology increased service availability, overall throughput and decreased bad developer experiences with circuit breakers on Checkpoint’s scheduler. These circuit breakers on the interface between systems in CI were levers to minimize cascading failures and provided high leverage for programmatic metric queries for multiple services instead of individual client or service based approaches.

🔗 References
- Balancing Safety and Velocity in CI/CD at Slack. “A story of evolving socio-technical workflows that increased developer velocity and redefined confident testing and deploy workflows at Slack.”
- Infrastructure Observability for Changing the Spend Curve. “A deep dive on how we crafted an order of magnitude change in our spend (10x reduction compared to baseline growth) over the last two years with iterative understanding and changes in Slack’s Continuous Integration (CI) infrastructure.”
- Deploys at Slack. Slack’s Continuous Delivery system built on top of Checkpoint.
- Continuous Integration. “Continuous Integration is a software development practice in which developers integrate, build, and test their work frequently, typically supported by automation.”
- Continuous Delivery Explained. AWS’s resource on defining Continuous Delivery vs Continuous Deployment. “Continuous delivery automates the entire software release process. Every revision that is committed triggers an automated flow that builds, tests, and then stages the update. The final decision to deploy to a live production environment is triggered by the developer.”
- Martin Fowler’s article on Circuit Breakers. “The basic idea behind the circuit breaker is very simple. You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all. Usually you’ll also want some kind of monitor alert if the circuit breaker trips.””
- Wikipedia’s article on Circuit Breakers. “A circuit breaker is an electrical safety device designed to protect an electrical circuit from damage caused by an overcurrent or short circuit. Its basic function is to interrupt current flow to protect equipment and to prevent the risk of fire. Unlike a fuse, which operates once and then must be replaced, a circuit breaker can be reset (either manually or automatically) to resume normal operation.”
- Circuit Breakers in Microservices. “The circuit breaker is a design pattern, used extensively in distributed systems to prevent cascading failures. In this post, we’ll go through the problem of cascading failures and go over how the circuit breaker pattern is used.”
- Pattern: Circuit Breaker in Clients. “How to prevent a network or service failure from cascading to other services?””
- Trickster, an Open-Source Dashboard Accelerator for Prometheus. Trickster was developed internally and recently made available open source. Written in Go, Trickster is a reverse proxy cache for the Prometheus HTTP APIv1 that considerably accelerates dashboard rendering times for any series queried from Prometheus. This is possible because of the delta proxy, step boundary normalization, and fast forward features.
- Test Sizes. Google’s article on defining a taxonomy for tests between small, medium, and large
- The Practical Test Pyramid. “The ‘Test Pyramid’ is a metaphor that tells us to group software tests into buckets of different granularity. It also gives an idea of how many tests we should have in each of these groups. Although the concept of the Test Pyramid has been around for a while, teams still struggle to put it into practice properly. This article revisits the original concept of the Test Pyramid and shows how you can put this into practice.”
- On the Diverse And Fantastical Shapes of Testing. “Pyramids, honeycombs, trophies, and the meaning of unit testing”
- What is incident analysis and why should we do it?. Laura Macguire’s article on performing incident analysis. “Service outages are a common part of modern software operations, especially if you’re moving fast or operating at scale! Many companies have realized this and have begun to invest in incident analysis in order to learn from their incidents. To introduce our Incident Analysis 101 series, let’s first talk about what exactly incident analysis is, and what benefits your teams can realize from it.”
- Are we getting better yet? Progress toward safer operations Alex Elman’s talk at SRECon. Key points: “Deeper understanding leads to better fixes and enduring prevention. Reliability is reported using SLOs (and error budgets) not incident metrics. Nobody has control over how an incident unfolds. Incidents are an opportunity to improve the accuracy of mental models. At least half of incident analysis should focus on human factors. Comparative storytelling enhances learning”
- Piper (ACM) “Google’s monolithic software repository, which is used by 95% of its software developers worldwide, meets the definition of an ultra-large-scale system, providing evidence the single-source repository model can be scaled successfully. The Google codebase includes approximately one billion files and has a history of approximately 35 million commits spanning Google’s entire 18-year existence. The repository contains 86TB of data, including approximately two billion lines of code in nine million unique source files. The total number of files also includes source files copied into release branches, files that are deleted at the latest revision, configuration files, documentation, and supporting data files”
- Monorepo maintenance (Github) “At GitHub, we serve some of the largest Git repositories on the planet. We also serve some of the fastest-growing repositories. Each day, the largest repositories we host become even larger. About a year ago, we noticed that the job we use to repack Git repositories began hitting our self-imposed timeouts on larger repositories. Even when expanding these timeouts, failing maintenance on these repositories has generally been the cause of degraded performance that is hard to mitigate.”
- The Repeat Incident Fallacy (DevOpsDays Rockies) “Incidents uh find a way” Brilliant talk by @themortalemily on incidents, learning, and optionality. It uses Jurassic Park to illustrate systems thinking for incident analysis.
Conference talks
🔧 Craft Conference (2022 June 02)
Accompanying Article
- slack.engineering article coming soon!